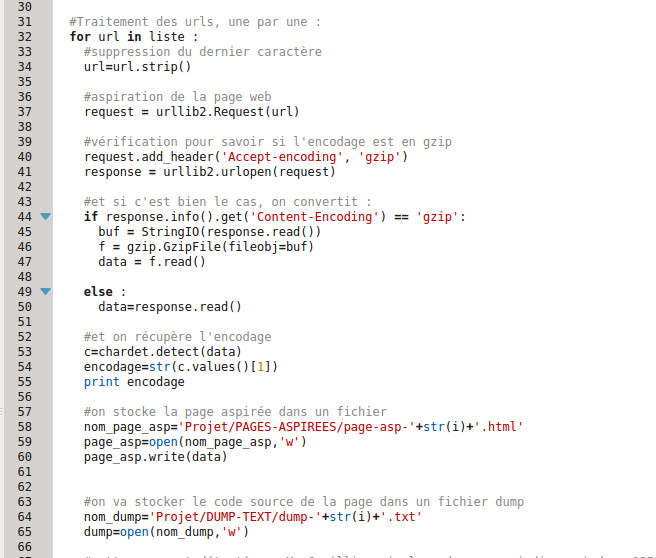
Il s’agit donc ici de :
– récupérer le contexte,
– écrire le contexte dans un fichier par url,
– créer un fichier global des contextes, qu’on utilisera dans les étapes suivantes du projet (étiquetage avec le Trameur, nuages de mots, etc).
Voici la partie du script qui s’occupe des contextes :
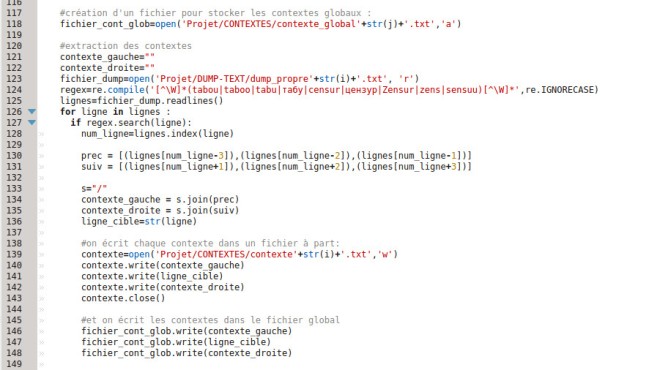
Dans un premier temps, on crée des chaînes de caractères vides qui correspondent respectivement au contexte gauche et au contexte droit.
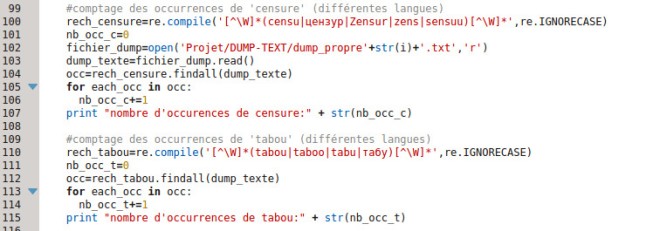
Ici, en ce qui concerne l’expression régulière, on n’a pas besoin de rechercher séparément les deux termes, comme on l’a fait pour le décompte des occurrences. Par contre, on la compile, à nouveau pour pouvoir utiliser le flag re.IGNORECASE pour ne pas tenir compte de la casse, comme pour le décompte des occurrences cette fois.
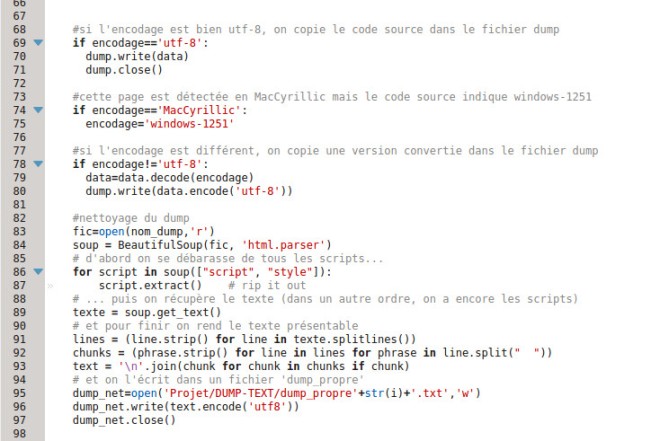
Ensuite, on ouvre le fichier dans lequel on a stocké le dump nettoyé. On va le parcourir ligne par ligne, et vérifier si la ligne en cours contient un des deux mots (ou leurs équivalents dans les différentes langues). Procéder ainsi permet de stocker dans la variable ‘lignes’ une liste de toutes les lignes du fichier. Ainsi, chaque a un index, du coup on a des numéros de ligne. Ce qui permet de récupérer la ligne cible ainsi que les trois précédentes et les trois suivantes. On ne veut qu’une ligne de texte, mais comme les dumps contiennent des sauts de ligne, on étend la distance.
On stocke chacune des lignes précédentes et suivantes dans une liste qu’on transforme ensuite en chaînes de caractères : ‘contexte_gauche’ et ‘contexte_droite’. On écrit ensuite ces chaînes de caractères ainsi que celle de la ligne cible (celle qui contient le mot) dans des fichiers séparés -qu’on referme ensuite) puis dans un fichier global de contextes.
Tous les fichiers de contextes, même les fichiers globaux, sont stockés dans le répertoire ‘CONTEXTES’. Il y a un fichier global par langue, dont le nom porte un indice ‘j’, qui correspond à un compteur de fichiers d’URLS (ce point sera développé dans un autre billet).