Pour l’écriture et l’encodage des dumps, le script se passe comme ça :
Ecriture des dumps
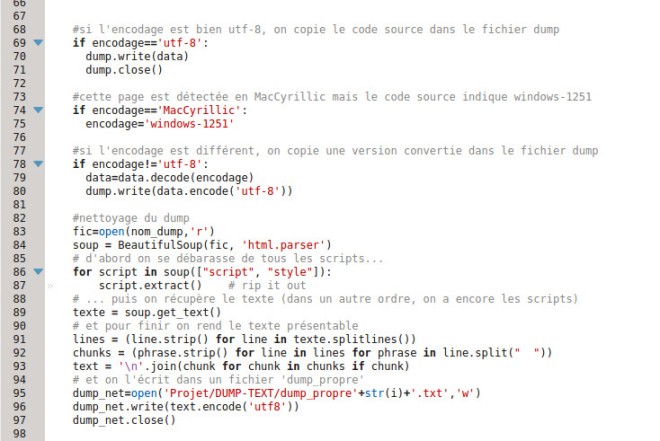
Et là, au niveau de l’encodage nous avons en théorie deux possibilités : soit c’est de l’utf-8, soit c’est autre chose. En pratique, nous avons ici trois conditions if, à cause d’une url dont l’encodage n’est pas correctement détecté. Je n’ai pas trouvé pourquoi, alors j’ai rajouté une condition pour cet encodage (MacCyrillic), lignes 78 à 80, qui remplace l’encodage erroné par le bon.
On rappelle que le contenu, le code source, est stocké dans la variable ‘data’, issue de l’étape précédente (décompression et/ou aspiration des pages). Les codes sources déjà en utf-8 sont écrits tels quels. Ceux dont l’encodage est différent sont écrit en étant converties en utf-8. La conversion se passe en deux temps : d’abord on utilise l’encodage ‘de base’ pour récupérer les données qu’on convertit ensuite en utf-8 pendant qu’on les écrit dans le fichier dump.
Nettoyage des dumps : BeautifulSoup
On passe ensuite au nettoyage des dumps. Qu’entend-on par nettoyage ? Les dumps, à ce stade-là, ne sont en fait que les codes sources des pages qu’on a aspirées, stockés dans des fichiers txt. Et qui dit ‘code source’, dit ‘tout un tas de choses’ qu’on peut considérer comme du bruit autour du texte sur lequel on veut faire notre analyse. On trouve là dedans : tout le code html, mais aussi – et c’est plus problématique – des scripts javascript.
A priori, on peut supprimer plutôt facilement le code html au moyen d’expressions régulières, puisque celui-ci est constitué de balises entre chevrons. Or il y a deux problèmes : je n’ai pas réussi à utiliser d’expression régulière en mode multiligne (grâce aux flags .MULTILINE et .DOTALL du module re), et ça ne supprime pas le script javascript entre les balises html épnoymes.
Comme lors de l’étape précédente, après moult lectures, je trouve une pise sérieuse : « BeautifulSoup ». Un nom loufque qui impressionne la novice mais qui intrigue la curieuse. En fait, BeautifulSoup vient de la bilbilthèque bs4, et permet grâce à parser.html (un module) de créer un objet ‘soup’ qui est en fait le code html, étiqueté. Il y a pas mal de fonctions très intéressantes. Par exemple, on peut ‘ranger’ le code avec .prettify(), qui indente correctement ledit code. Mais on peut aussi, parce que nous ne sommes vraiment pas les premiers à vouloir extraire du texte d’une page html, récupérer directement le texte de la page au moyen de .get_text().
Vous vous souvenez, je vous ai dit que le javascript était plus problématique que le html… Eh bien voilà pourquoi : même avec la formidable BeautifulSoup, on ne parvient pas à s’en débarasser. Enfin si, on y arrive, mais pas du premier coup. En fait, il faut commencer par repérer tout ce qui est ‘rangé’ comme étant du script ou du style, et le supprimer. Et récupérer le texte après avec get_text(). C’est vraiment dans cet ordre-là que ça fonctionne le mieux. Après ce nettoyage, les dump sont presque nickel : il reste, parfois, une petite coquille dans un dump. Mais c’est vraiment négligeable par rapport à tout ce que j’ai obtenu en essayant autrement. Un autre point négatif : il reste beaucoup de lignes blanches dans les dump, on en tiendra compte dans la recherche de contexte.
Pour finir, avant d’écrire le dump propre dans un fichier, on rend le texte présentable avec une série de découpages (le texte en ligne, la ligne en « phrases » et les « phrases » en « chunks ») pour supprimer les derniers caractères avant de tout reconcaténer dans une variable ‘text’, celle qui contient le dump propre, et qu’on écrit. Soit dit en passant, on l’encode directement en utf-8, comme ça on est tranquilles.
Et on referme le fichier !
