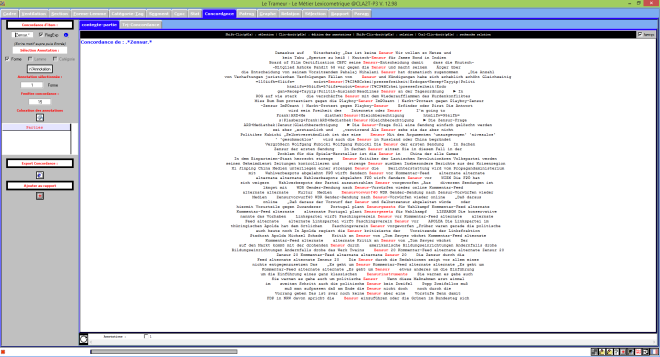
La vengeance du Trameur

Le Retour du Trameur
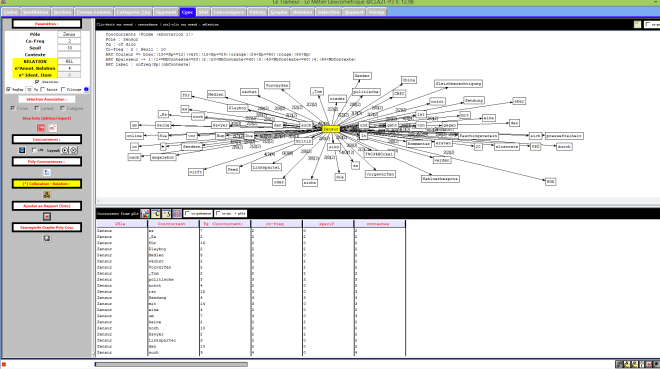
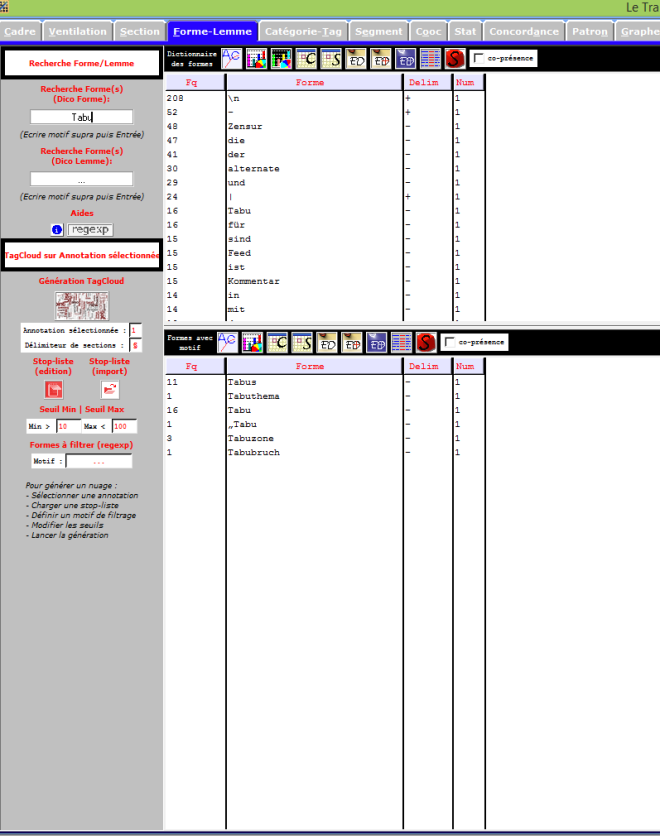
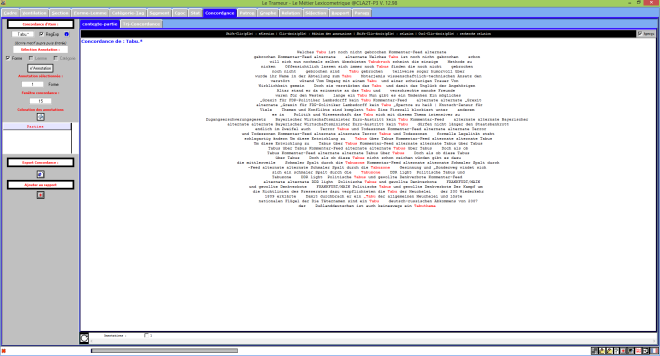
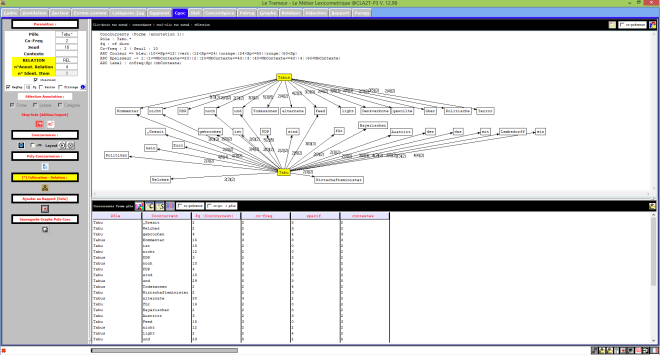
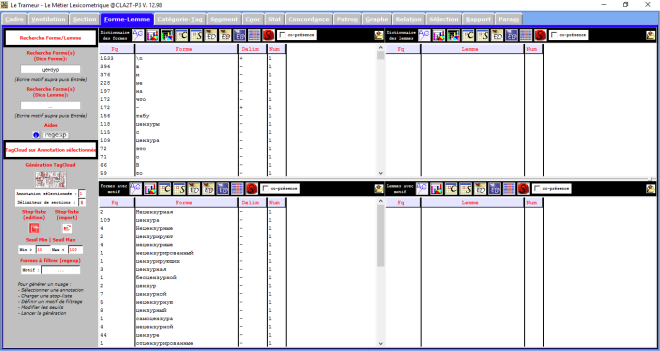
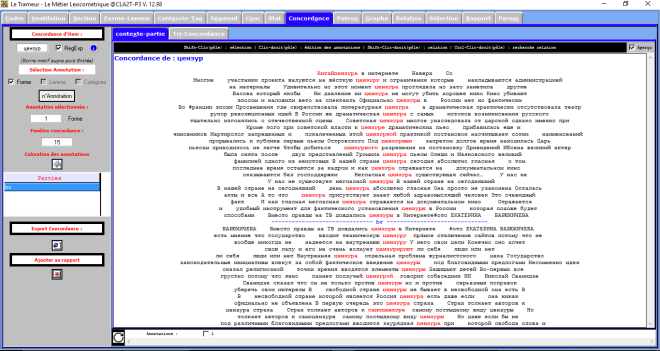
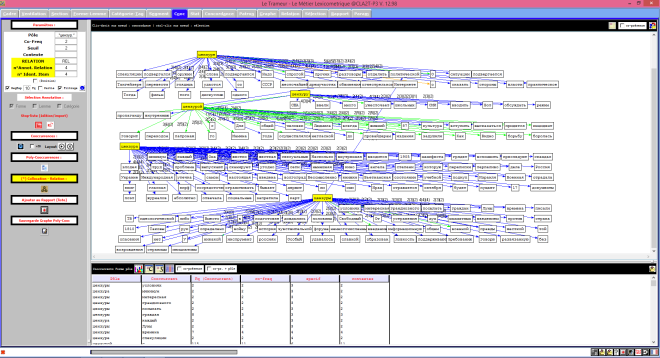
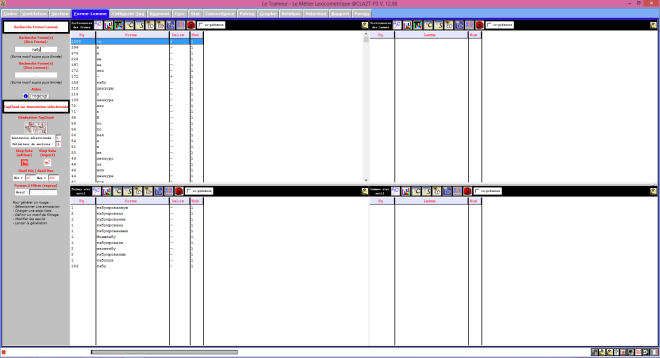
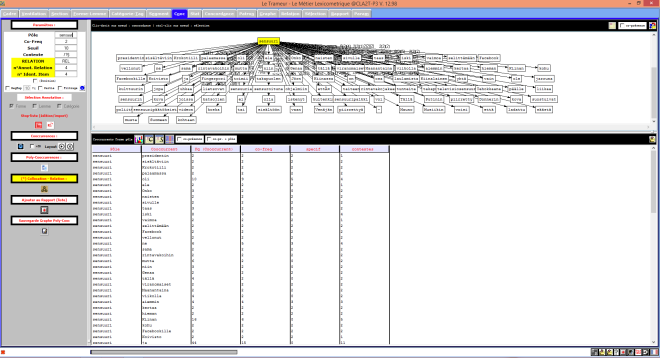
Le Trameur en Russie
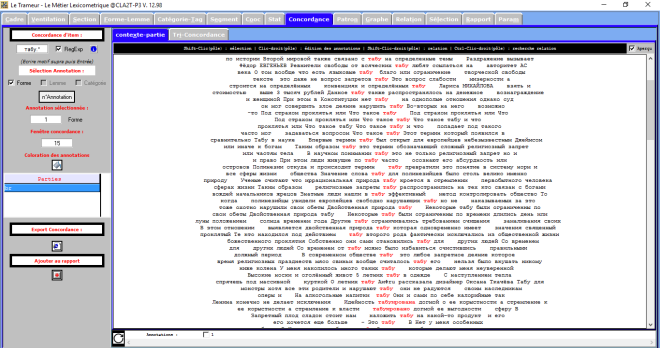
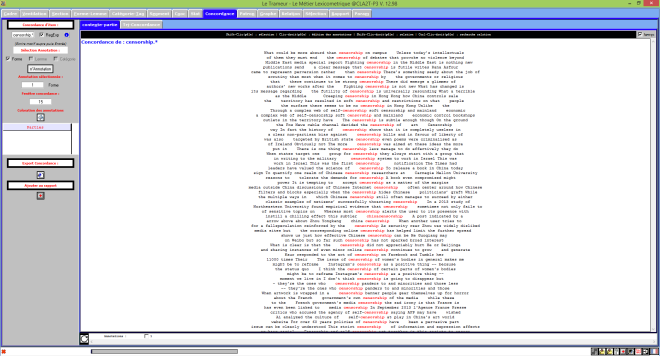
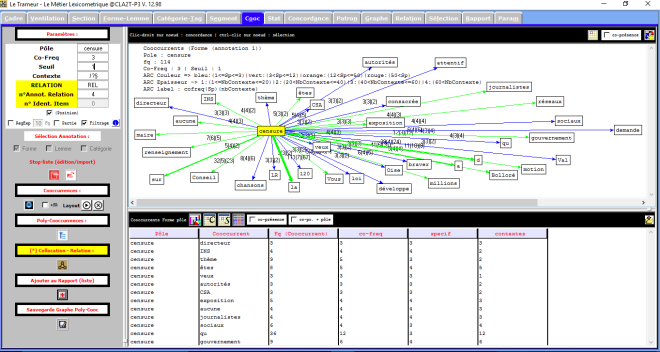
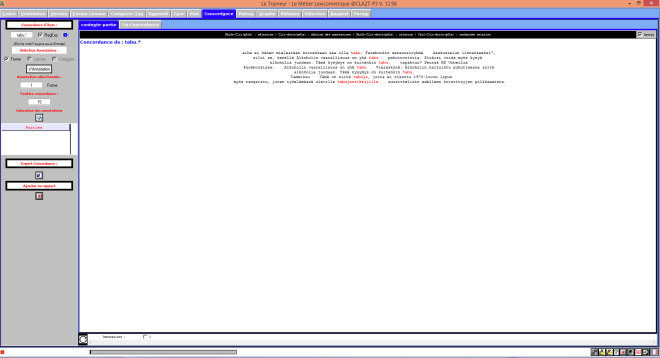
Trameur VS contextes en français
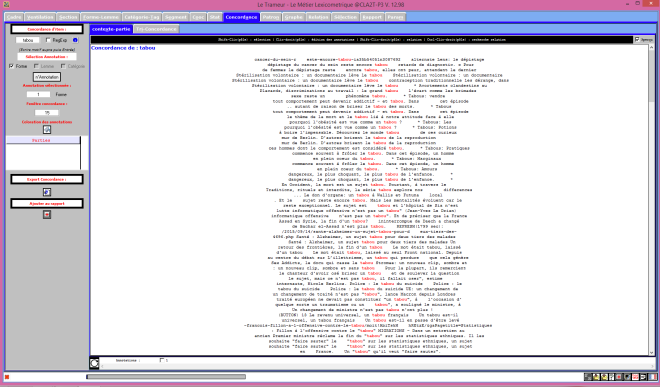
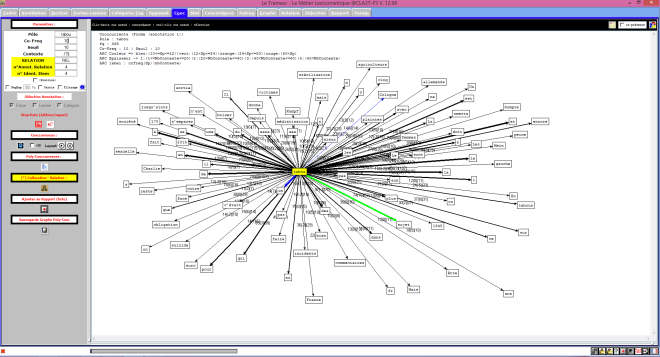
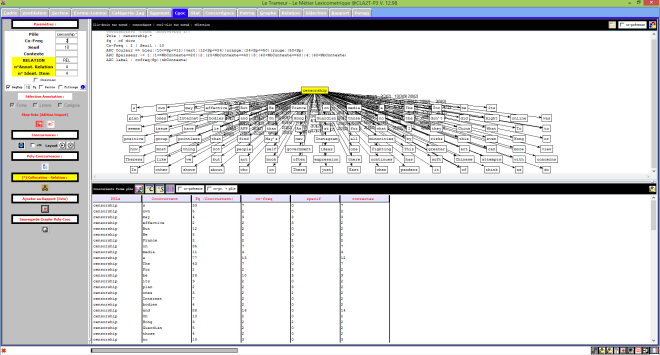
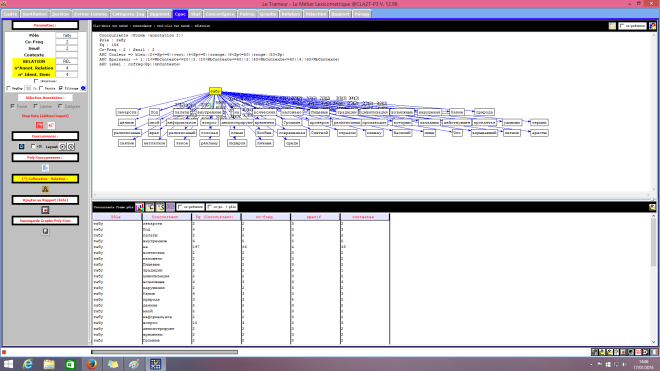
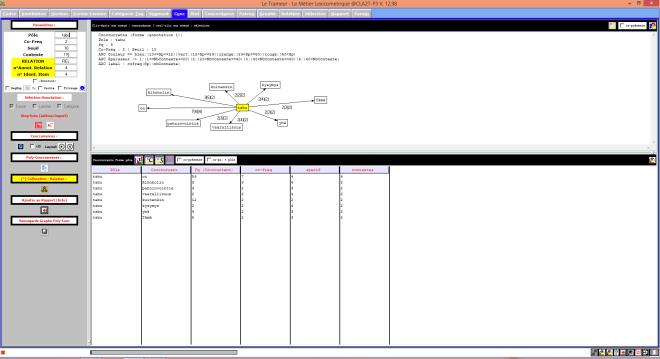
Les contextes du finnois passés au Trameur
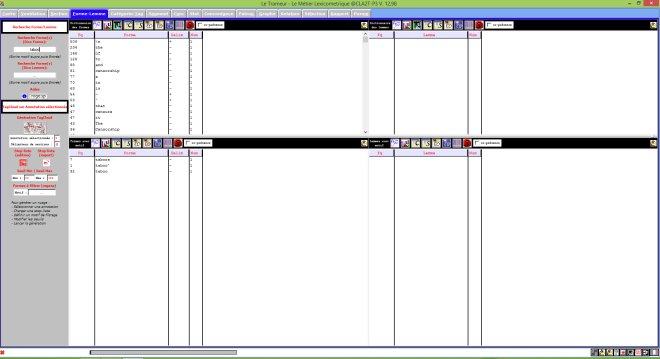
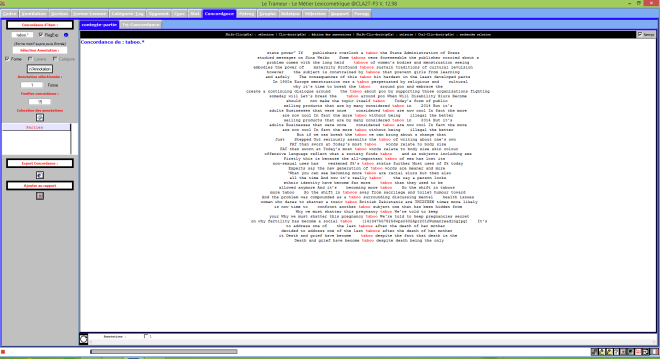
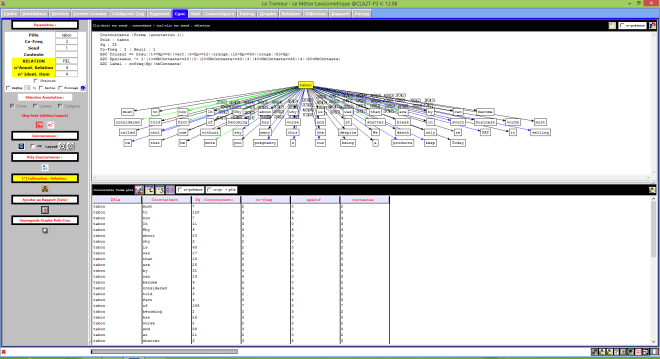
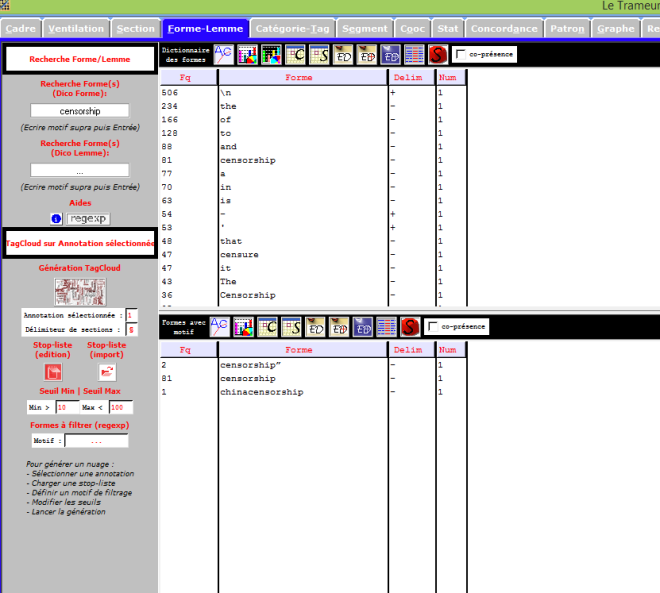
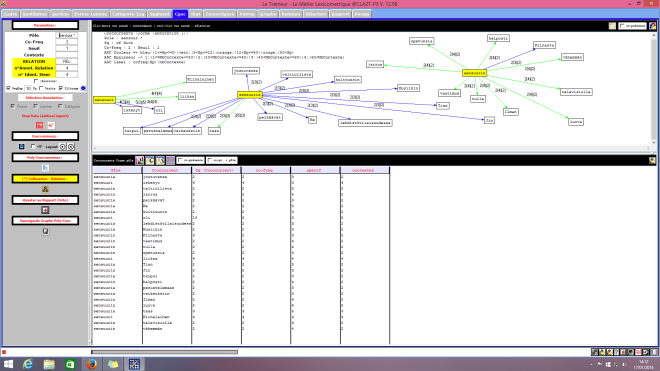
Le Trameur est un logiciel de Textométrie développé par les enseignants-chercheurs de Paris 3 : il permet d’effectuer de nombreuses analyses à partir de données textuelles. Il calcule, entre autre, les fréquences des unités lexicales.
Script bash version améliorée

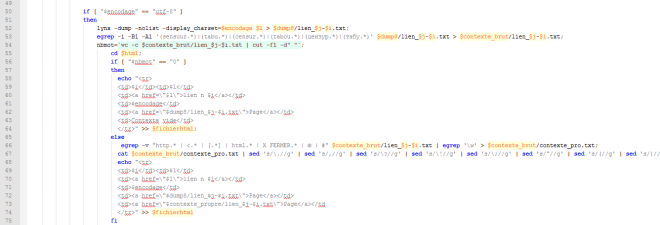

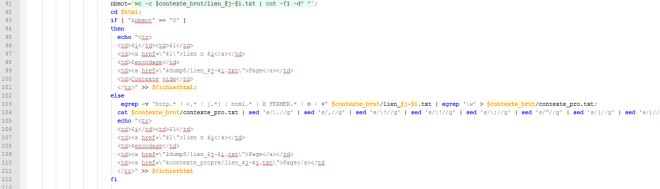

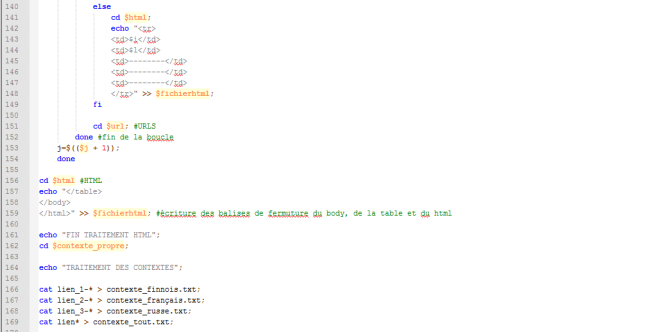
Le script bash étape par étape (1)
Le script suivant s’exécute en entrant la commande suivante à l’endroit de l’arborescence où a été situé notre environnement de travail :
bash ./PROGRAMMES/script.sh < ./PROGRAMMES/input.txt

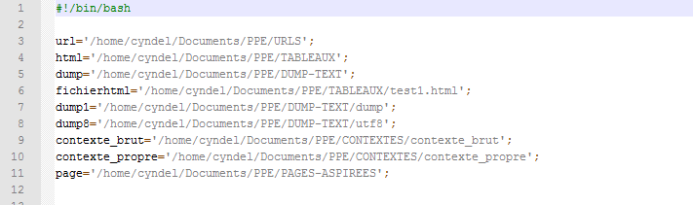
read ligne 2 et 3 : lecture des chemins, « dossier » correspond au dossier contenant les fichiers d’URL (un par langue) et « fichier » le fichier résultat. Les chemins on été stockés dans le fichier texte input.
rm : nettoyage des dossiers de travail
echo « <html>…. » > $fichier ; => écriture du code html dans un fichier dont le chemin a été indiqué ligne 3
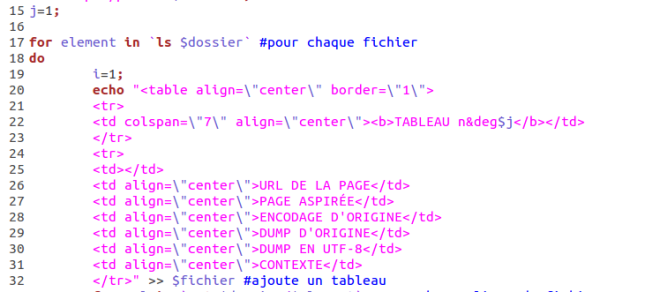
ligne 15 : le compteur de tableau est mis à 1
ligne 17 : début de la première boucle qui traitera les fichiers
ligne 19 : le compteur des lignes est mis à 1
ligne 20-32 : on ajoute un tableau au fichier pour chaque fichier trouvé dans le dossier URLS
Le site du projet !
Tout est plus ou moins dit dans le titre du billet, et puis j’en ai déjà parlé dans un billet précédent. Le projet dont on parle sur ce blog s’accompagne de la construction d’un site qui présente le tout.
Comme je le mentionnais dans un autre billet, le site est en cours : l’architecture est finie, et nous sommes actuellement en train de le remplir.
Vous avez le droit à un petit coup d’oeil :
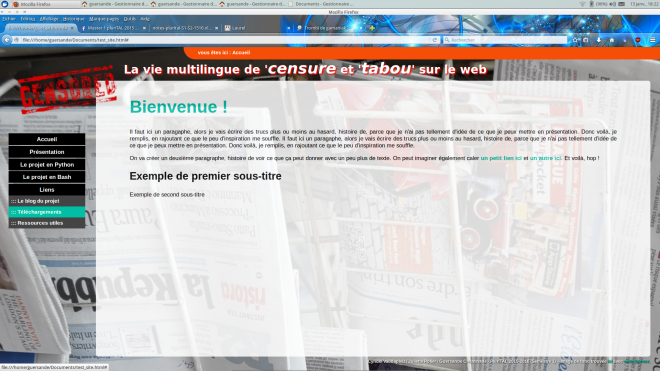
Il ne faut pas tenir compte du contenu sur l’image ci-dessus, c’était juste histoire de se faire une idée. Pratiquement tout est fait en html et en css. Il y a juste un tout petit morceau de javascript pour le menu déroulant ; sinon toute la mise en page est réalisée grâce au css. C’est quand même beaucoup plus pratique que la mise en page par tableaux, et c’est plus simple (je trouve) de mettre en place une mise en page qui s’adapte à la taille de l’écran de l’utilisateur. Et puis c’est tout de même plus flexible. Un dernier argument : on peut mettre des images transparentes par dessus le contenu ! Et ça, avec une mise en page par tableau…
A bientôt !
Python – Traitement de plusieurs fichiers d’URLS
Alors bon, pour le coup, je fais probablement les choses à l’envers. Dans la version bash, on traite tous les fichiers urls en une seule exécution du script. Au stade où en est le script python, il ne traite qu’un seul fichier à la fois. La raison est très simple : je n’ai pas réussi à insérer ma première boucle for (qui parcourt les lignes du fichier) dans une autre boucle for (qui parcourt le contenu du dossier ‘URLS’).
Pour que tous les fichiers puissent être traités en une seule exécution du script, c’est pourtant nécessaire, à priori. J’imagine bien la petite subtilité en fait très simple, que j’ai cherchée pendant des semaines sans finir par la trouver.
Alors j’ai décidé de faire autrement. J’ai transformé ce qui était le script complet en une fonction :
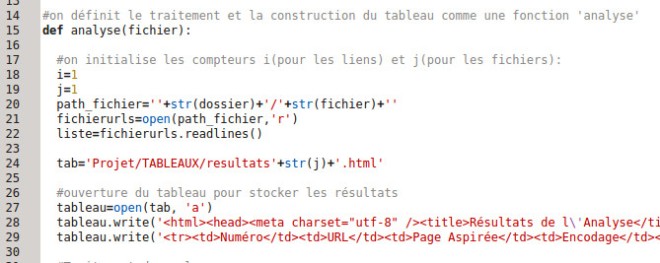
La fonction est donc analyse() et elle prend un argument ‘fichier’, qui correspond à un des fichiers du dossier d’URLS. On ne traite encore qu’un seul fichier, me direz-vous. Eh bien non. Regardez pourquoi :

On invite l’utilisateur à indiquer le chemin pour joindre son dossier d’URLS. Grâce à la fonction listdir() du module os, qui permet de gérer les fichiers et répertoires sous python, on obtient une liste donc chaque élément est un des fichiers du dossier.
Et c’est donc là que je place la fameuse boucle for qui me manquait : pour chaque élément de la liste de fichiers, pour chaque fichier donc, on applique le l’analyse. On note au passage la déclaration du compteur j, qui s’incrémente à chaque fois qu’un fichier est traité. C’est ce qui permet d’avoir un fichier global de contexte par langue, et que chaque fichier global ait un nom différent.
On ouvre chaque fichier d’urls en spécifiant le chemin d’après ce que l’utilisateur a renseigné, et on transforme son contenu en liste d’urls.
On stocke les résulats dans un tableau écrit dans une page html. Comme pour les fichiers de contexte, il y a un fichier de résultat par langue.
