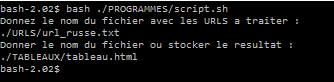
Encore une fois, ce post vient compléter son pendant en bash, qui porte un nom quasi-identique.
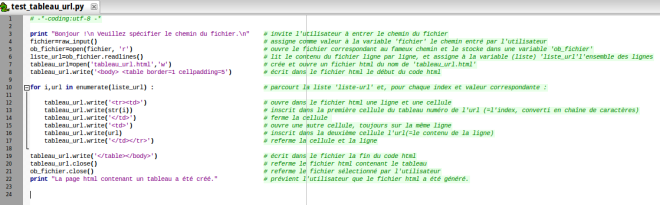
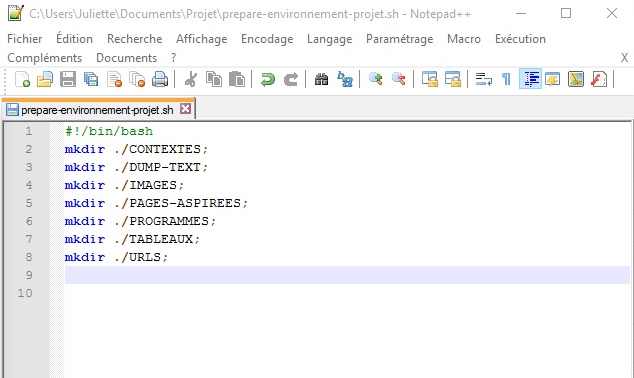
Voici le script en python : 
Pour qu’on puisse bien voir le code (dont l’image ci-dessus est assez large), les commentaires ont été tronqués.
Voici l’explication du code :
Première étape
Dans un premier temps, on importe plusieurs fonctions du module ‘os’ de python, où ‘os’ correspond à ‘operating system’. Il y a probablement plus simple que le code proposé ci-dessus, mais comme je découvre petit à petit ce module, je me contente pour l’instant de cette solution. Si le code devient trop compliqué, j’essaierai d’utiliser d’autres fonctions de ce module (très riche) pour optimiser le script.
Une fois le module importé, on affiche grâce à la fonction getcwd() le répertoire courant. On demande ensuite à l’utilisateur s’il s’agit du bon répertoire. Si la réponse est « oui », il ne se passe rien. Si la réponse est « non », on demande à l’utilisateur de saisir le chemin de son répertoire (chemin absolu). Puis, à l’aide de la fonction chdir, on se rend dans ce répertoire. On confirme ensuite le répertoire de travail en l’indiquant à l’utilisateur.
Deuxième étape
Transformation du ‘contenu’ du répertoire en liste :
La fonction listdir() permet de créer une liste (appelée ici liste_fichiers) dans laquelle on stocke les différents noms de fichiers.
J’ai rencontré des problèmes avec le module path, j’ai donc utilisé ce système de liste pour contourner le problème.
Utilisation d’une boucle for pour parcourir la liste :
La boucle permet, pour chaque fichier :
- de supprimer l’extension de son nom
- de générer un nom de tableau correspondant (cela permet à la page HTML contenant le tableau d’avoir le même nom que le fichier URL correspondant, à ceci près qu’on précise qu’il s’agit d’un tableau).
- de générer la page HTML qui contiendra ce tableau
- d’écrire dans le fichier ce qui le fait devenir une page HTML : les balises HTML de la page, ainsi que l’ouverture et la fermeture du tableau
- une autre boucle for, enchâssée dans le tableau mentionné au point précédent.
En outre, l’utilisateur est prévenu de la liste de fichiers qui vont être générés et du nom qu’ils auront.
Une boucle for dans une boucle for :
La seconde boucle for, qui s’étend de la ligne 34 à la ligne 38, permet pour chaque ligne du fichier (autrement dit pour chaque URL) de créer une ligne dans le tableau, dans laquelle il y a deux cellules : une pour indexer l’URL, et l’autre pour l’URL en question.
Le fait que cette boucle soit incluse dans la première boucle fait que, pour chaque fichier du répertoire, on génère une page HTML contenant un tableau (boucle 1) dans lequel, pour chaque URL, une ligne est générée (boucle 2).
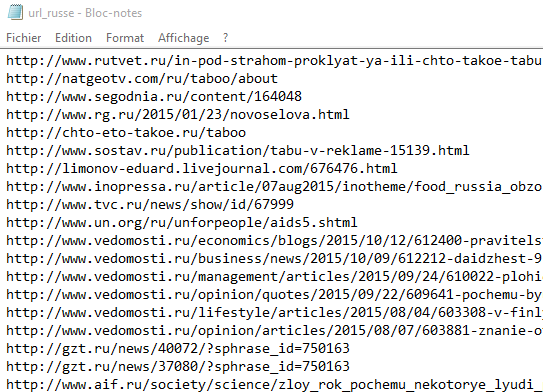
Exemple de rendu :

Etant donné que mes fichiers URL sont ‘malades’, et que je n’ai pas encore corrigé le souci, je vous présente ici un exemple avec un fichier fictif contenant des URL fictives.
Remarques
On peut voir que des problèmes ont été réglés :
- On peut gérer plusieurs fichiers d’URL en même temps. La solution proposée ici permet de gérer un nombre potentiellement important de fichiers URL.
- La page HTML générée est lisible : les \n (retour à la ligne) et \t (tabulations) assurent l’indentation correcte d’un code HTML.
Finalement, la première boucle for permet de refermer chaque fichier HTML, après avoir refermé les tableaux.
Evidemment, ce code peut encore être amélioré, mais ce sera l’objet d’un prochain post ! A bientôt, donc.