Avant toute chose, voici la partie du script responsable de la récupération des pages :
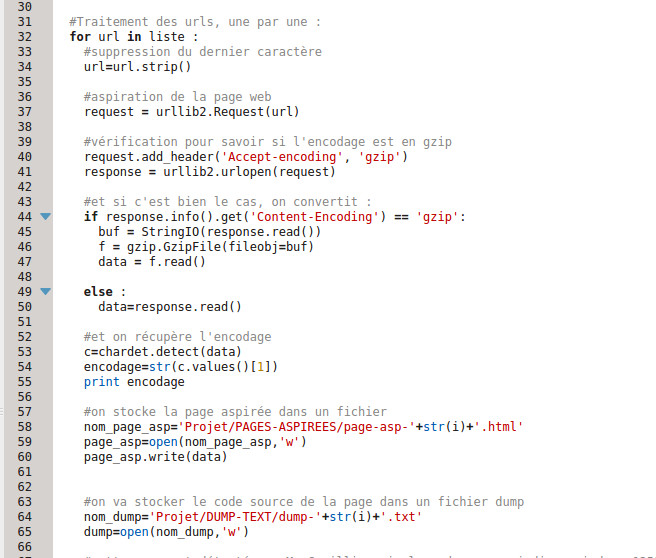
La variable « liste » est le résultat de la commande liste=fichierurls.readlines(), c’est donc le contenu d’un fichier urls, lu ligne par ligne, et stocké dans une liste. Liste que l’on parcourt url par url, en effectuant les traitements suivants.
Dans un premier temps, on supprime le dernier caractère de l’url. Je ne l’avais pas fait au départ, et j’avais énormément d’erreurs de requêtes HTTP. Il m’en reste encore quelques unes (ça fait partie des erreurs mentionnées dans mon billet précédent, celles que je corrigerai en dernier lieu).
Ce qui nous amène donc à l’aspiration de la page web à proprement parler. Pour ce faire, j’ai utilisé la bibliothèque urllib2 de python. La documentation officielle de python est ici
Dans un premier temps, on fait une requête : request = urllib2.Request(url), qui nous donne un objet Request (request), qui va nous servir à ouvrir l’url.
La ligne request.add_header(‘Accept-encoding’, ‘gzip’) permet de résoudre un problème lié à l’encodage et aux manipulations qu’on souhaite faire après. Pour récupérer l’encodage de la page, on utilise la fonction detect de chardet, qui renvoie une variable de type dictionnaire :
{'encoding': 'utf-8', 'confidence': 0.99}
C’est plutôt explicite : à gauche l’encodage, à droite un taux de fiabilité de la détection, allant de 0 à 1 (où 1 est à 100% fiable). Il est possible d’adapter les traitements que l’on veut appliquer après selon le degré de fiabilité de l’encodage détecté. En exécutant le script, je n’ai trouvé que des taux de ‘confidence’ très hauts, donc je n’ai pas rajouté de conditions.
Le problème dans un premier temps, c’était que pour la majorité des urls, j’obtenais ‘None’ en tant que ‘encoding’. Après de nombreuses recherches et lectures sur internet, j’ai cru comprendre que le contenu des pages était parfois compressés au moyen d’algorithmes de compression HTTP(ici), l’un de ces algorithmes étant gzip. Et dans ces cas-là, chardet.detect ne trouve pas d’encodage, qui est pourtant mentionné dans le code source. Un peu plus loin, j’ai lu que l’on pouvait utiliser une bibliothèque du nom de gzip, grâce à laquelle on peut vérifier si la valeur de ‘Content-Encoding’ était ou non « gzip ». Et si oui, décompresser ledit contenu.
Ce n’est pas tellement utile pour l’aspiration en elle-même, ça l’est pour l’encodage. Mais, comme on vient de le voir, il faut intervenir après la requête, et avant de stocker la page aspirée dans le dossier approprié. Et donc, pour extraire le nom de l’encodage a proprement parler, on extrait la valeur grâce à .values (c étant une variable de type dicitonnaire) la valeur du premier champ de « l’entrée » du dictionnaire (‘encodin’: ‘utf-8’).
Pour finir, on stocke la page dans le dossier des pages aspirées, en insérant le numéro de l’url dans le nom du fichier html. Un lien vers chaque page aspirée est inséré dans une colonne du tableau de résultats. Tableau dans lequel on rajoute par ailleurs une autre colonne où on indique l’encodage.
A ce stade, le tableau ressemble à ceci (mais en beaucoup plus long).

A propos de la lecture et de la fermeture de fichiers en python : on utilise des variables buffer (‘buf’ ou ‘response’, par exemple), comme objet intermédiaire dans les traitements.
Les dernières lignes qu’on voit sur la capture écran servent à créer les fichiers dans lesquels on va stocker les codes sources des pages, et à ouvrir les fichiers en question (un seul fichier à la fois, par url).
